
Publié le 03 octobre 2025. Anthropic, l’entreprise derrière l’intelligence artificielle Claude, a reconnu que trois défaillances techniques distinctes ont récemment affecté la qualité des réponses de ses modèles. Ces incidents, désormais résolus, ont mis en lumière les défis liés à la gestion d’une infrastructure complexe opérant sur plusieurs plateformes matérielles.
- Trois bogues d’infrastructure ont dégradé par intermittence la qualité des réponses de l’IA Claude en août et début septembre 2025.
- Ces problèmes n’étaient pas liés à une surcharge du service, mais à des défaillances internes dans le routage, la logique ou les pipelines de compilation.
- Anthropic déploie Claude sur AWS Trainium, GPU NVIDIA et TPU Google, une complexité qui exige une validation rigoureuse sur chaque plateforme.
Durant les mois d’août et de début septembre 2025, des utilisateurs de Claude AI ont signalé des réponses incohérentes ou de moindre qualité. Initialement interprétés comme des variations normales de performance, ces incidents ont été identifiés comme étant le résultat de trois bogues d’infrastructure distincts. L’entreprise assure que ces problèmes n’étaient en aucun cas dus à une demande accrue ou à une charge serveur élevée.
Dans un communiqué, Anthropic a précisé que « Les problèmes signalés par nos utilisateurs étaient dus uniquement à des bogues d’infrastructure (…) Chaque bogue a produit des symptômes différents sur différentes plateformes à des taux variés. Cela a créé un mélange confus de rapports qui ne pointaient pas vers une cause unique. »
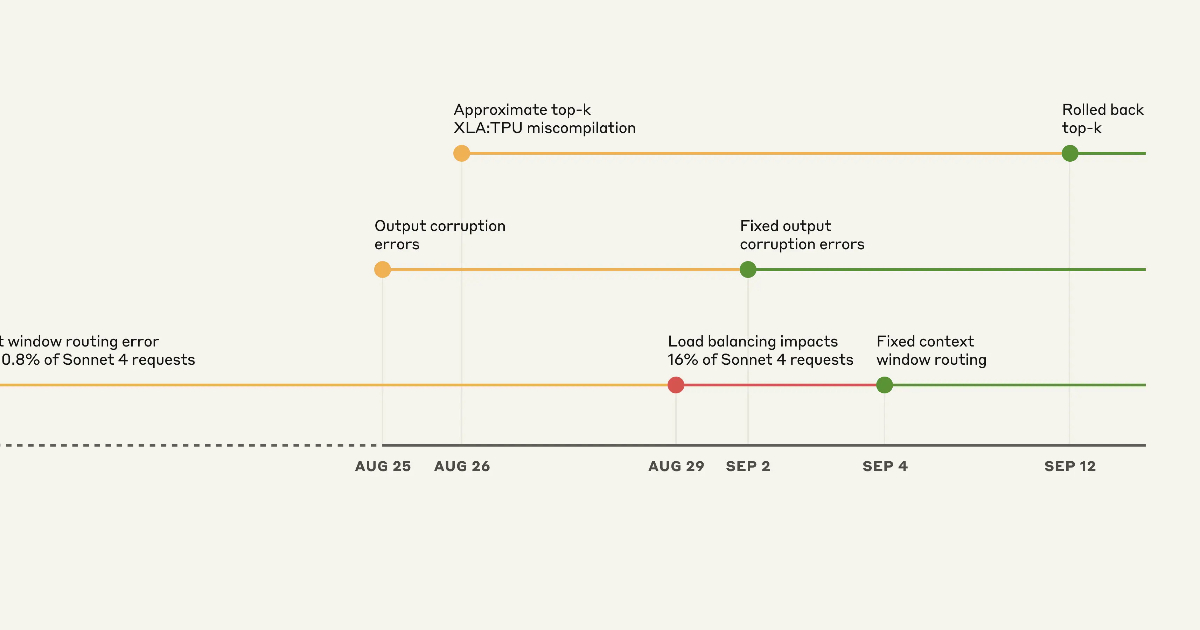
Les trois problèmes identifiés sont les suivants :
- Une erreur de routage dans la gestion des fenêtres de contexte a affecté 16 % des requêtes Sonnet 4 le 31 août, moment le plus critique.
- Une corruption de sortie, causée par une mauvaise configuration des serveurs API Claude TPU, a entraîné une erreur lors de la génération de jetons. Ce problème a impacté les requêtes adressées aux versions 4.1 et 4 de l’opus entre le 25 et le 28 août, ainsi que celles destinées à Sonnet 4 du 25 août au 2 septembre.
- Un bogue latent dans le compilateur TPU Top-K a affecté les requêtes adressées à Claude Haiku 3.5 pendant près de deux semaines.
Anthropic a souligné son engagement à maintenir des standards d’équivalence stricts pour ses modèles, malgré leur déploiement sur diverses plateformes matérielles, notamment AWS Trainium, les GPU NVIDIA et les TPU Google. « Nous déployons Claude sur plusieurs plateformes matérielles, à savoir AWS Trainium, GPU NVIDIA et TPU Google. Chaque plateforme matérielle possède des caractéristiques différentes et nécessite des optimisations spécifiques. Malgré ces variations, nous avons des normes d’équivalence strictes pour les implémentations du modèle », a précisé l’entreprise.
Todd Underwood, responsable de la fiabilité chez Anthropic, a reconnu les difficultés rencontrées. Sur son compte LinkedIn, il a déclaré : « Cela a été un été difficile pour nous, en termes de fiabilité. Avant cet ensemble de problèmes, nous avions déjà rencontré des problèmes de capacité et de fiabilité tout au long de juillet et août (…) Je suis sincèrement désolé pour ces désagréments et nous travaillons dur pour vous fournir les meilleurs modèles avec le plus haut niveau de qualité et de disponibilité possible. »
Clive Chan, membre du personnel technique d’OpenAI, a commenté la complexité du domaine : « L’infrastructure d’apprentissage automatique est véritablement ardue. Excellent travail à tous ceux qui ont participé au débogage et à la résolution de ces problèmes. »
La volonté d’Anthropic est de rendre les différentes plateformes matérielles transparentes pour les utilisateurs finaux, afin que chacun reçoive des réponses de qualité équivalente, quelle que soit la plateforme qui traite sa requête. Cette objectif complexifie la gestion des infrastructures, chaque modification nécessitant une validation sur l’ensemble des plateformes et configurations. Comme l’a noté Philipp Schmid, ingénieur principal en relations développeurs IA chez Google Deepmind : « Servir un modèle à grande échelle est difficile. Le servir sur trois plateformes matérielles (AWS Trainium, GPU NVIDIA, Google TPU) tout en maintenant une équivalence stricte est un tout autre niveau. Cela pousse à se demander si la flexibilité matérielle vaut vraiment la peine en termes de vitesse de développement et d’expérience client pour eux. »
Sur la plateforme Hacker News, Mike Hearn a suggéré : « La chose la plus intéressante à ce sujet est l’absence apparente de tests unitaires. Le test pour le bogue du compilateur XLA se contente d’imprimer les sorties, ressemblant davantage à un cas de reproduction qu’à un test unitaire au sens où il serait exécuté par un cadre de test et suivi en termes de couverture. Et les équipes doivent simplement s’appuyer plus agressivement sur les tests. »
Pour l’avenir, Anthropic promet d’introduire des évaluations plus sensibles, d’intégrer des contrôles de qualité à davantage d’étapes, et de développer des infrastructures et des outils pour améliorer le retour d’information de la communauté, tout en préservant la confidentialité des utilisateurs.