
Publié le 26 février 2026 16:04:00. Pinterest a considérablement amélioré la vitesse et l’efficacité de son infrastructure d’ingestion de données, réduisant la latence de 24 heures à seulement 15 minutes grâce à une nouvelle approche basée sur la capture de données modifiées (CDC). Cette modernisation permet un accès plus rapide aux données pour l’analyse, l’apprentissage automatique et les fonctionnalités produit.
- Pinterest a mis en place un nouveau système d’ingestion de bases de données basé sur la capture de données modifiées (CDC).
- Ce nouveau système réduit la latence de l’accès aux données de 24 heures à 15 minutes.
- L’infrastructure optimisée permet des économies significatives en termes de coûts et de ressources.
L’entreprise a abandonné son ancienne infrastructure, caractérisée par des pipelines indépendants et des traitements par lots de tables complètes, qui se révélaient lents, complexes à gérer et coûteux. Les processus existants étaient inefficaces : même lorsque les modifications quotidiennes dans une table étaient inférieures à 5 %, l’intégralité de la table était traitée, gaspillant ainsi des ressources de calcul et de stockage précieuses. De plus, le système ne prenait pas en charge nativement les suppressions au niveau des lignes, et la fragmentation opérationnelle entraînait des incohérences dans la qualité des données et une maintenance lourde.
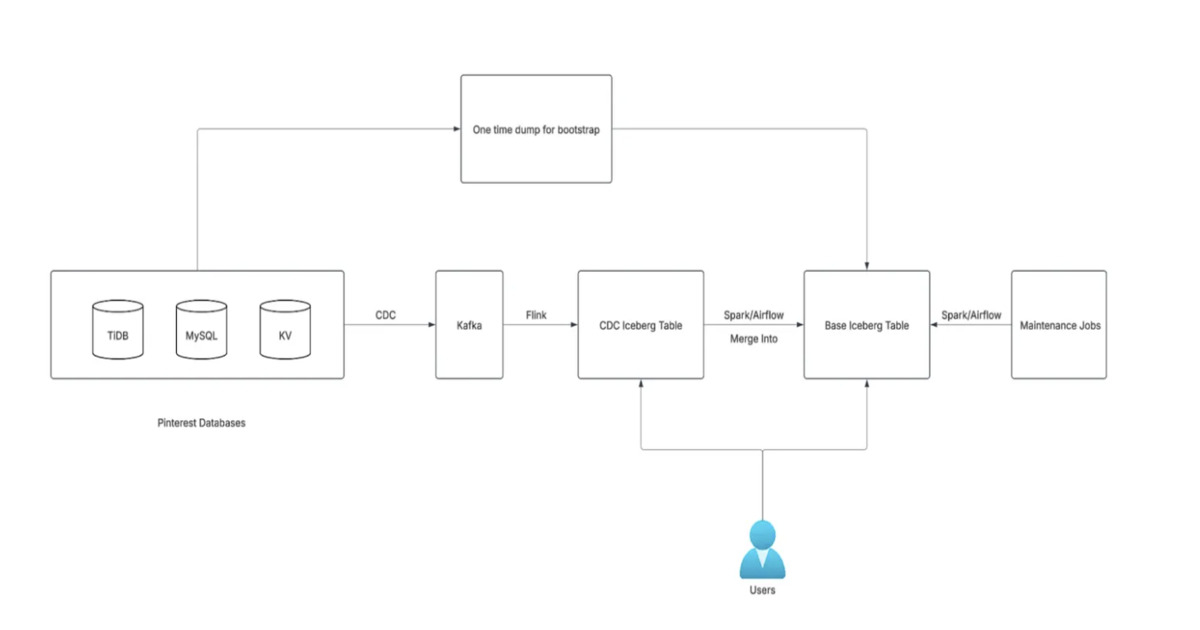
Le nouveau cadre d’ingestion unifié s’appuie sur des technologies telles que Change Data Capture (CDC) via Debezium et TiCDC, Kafka, Flink, Spark et Iceberg. Comme l’a souligné un ingénieur de Pinterest :
« Un cadre d’ingestion de base de données unifié basé sur Change Data Capture, Kafka, Flink, Spark et Iceberg permet d’accéder aux modifications de bases de données en ligne en quelques minutes (et non en heures ou en jours) tout en traitant uniquement les enregistrements modifiés, ce qui entraîne d’importantes économies de coûts d’infrastructure. »
Ingénieur Pinterest
Le framework est conçu pour être générique et prend en charge plusieurs systèmes de gestion de bases de données, notamment MySQL, TiDB et KVStore. Sa configuration est simple, facilitant l’intégration de nouvelles sources de données, et il intègre une surveillance avec des garanties de livraison des données au moins une fois.
L’architecture sépare les tables CDC des tables de base. Les tables CDC fonctionnent comme des journaux d’événements, enregistrant chaque modification avec une latence typique inférieure à cinq minutes. Les tables de base conservent un historique complet, mis à jour toutes les 15 minutes à une heure via des opérations Merge Into dans Iceberg. Pinterest a choisi la stratégie de « fusion en lecture » (Merge on Read – MOR) plutôt que la stratégie « copier en écriture » (Copy on Write – COW), car cette dernière entraînait des coûts de stockage excessivement élevés.
Les tâches Spark dédupliquent les dernières modifications des tables CDC avant de les appliquer aux tables de base. Un pipeline d’amorçage initial charge les données historiques, tandis que des tâches de maintenance continues gèrent la compaction et l’expiration des instantanés. Des optimisations, telles que le partitionnement des tables de base par hachage de la clé primaire à l’aide du bucketing Iceberg, permettent à Spark de paralléliser les mises à jour et de réduire la quantité de données analysées.
Les résultats obtenus sont significatifs : la latence de disponibilité des données a été réduite de plus de 24 heures à seulement 15 minutes, et seuls 5 % des enregistrements modifiés quotidiennement sont désormais traités. Le système gère des données à l’échelle du pétaoctet sur des milliers de pipelines, tout en prenant en charge les mises à jour et les suppressions incrémentielles.
Pinterest prévoit d’améliorer encore son système d’ingestion de données en automatisant l’évolution des schémas, afin de propager en toute sécurité les modifications en amont et en aval et d’améliorer ainsi la fiabilité et la maintenabilité des pipelines à grande échelle. Le framework d’ingestion basé sur CDC offre un accès en temps réel aux modifications de la base de données, avec des tables Iceberg sur AWS S3 et Flink-Spark gérant les charges de travail en streaming et par lots.