

Publié le 9 février 2026 17:01:00. L’intelligence artificielle, bien qu’elle révolutionne le domaine juridique, présente des failles insoupçonnées. Au-delà des erreurs flagrantes, c’est l’incapacité à garantir l’exhaustivité des recherches qui représente un risque majeur, notamment dans les litiges complexes comme ceux liés aux brevets.
- Les « hallucinations » de l’IA, bien que préoccupantes, sont potentiellement détectables par un contrôle humain.
- Le véritable danger réside dans l’omission de données pertinentes, un « inconnu inconnu » que l’IA seule ne peut identifier.
- Une infrastructure robuste, capable de traiter des volumes massifs de données, est essentielle pour minimiser ces risques.
L’intelligence artificielle est de plus en plus présente dans les cabinets d’avocats, mais son utilisation n’est pas sans risque. Si les erreurs d’IA, ou « hallucinations », font régulièrement la une des journaux, un autre problème, plus subtil et potentiellement plus dangereux, commence à émerger : l’incomplétude des résultats.
Si les hallucinations peuvent être repérées par un regard humain attentif – une citation incorrecte ou inexistante est généralement facile à identifier – l’omission d’un document pertinent est beaucoup plus difficile à détecter. Il ne s’agit plus d’une erreur, mais d’une absence d’information, un « inconnu inconnu » qui peut avoir des conséquences désastreuses, en particulier dans le domaine sensible des brevets.
Une étude de cas récente, menée par la société d’analyse de brevets Melange, illustre parfaitement ce risque. Melange a développé des outils de recherche et de cartographie des brevets pour aider ses clients à évaluer la validité de leurs droits de propriété intellectuelle. L’enjeu est de taille : le coût moyen d’un litige en matière de brevets se situe entre 2,3 et 4 millions de dollars (USD), et les dommages et intérêts peuvent atteindre environ 24 millions de dollars (USD). Un seul document d’antériorité oublié peut donc modifier radicalement l’issue d’un procès.
Selon Joshua Beck, PDG de Melange, l’entreprise conserve à vie tout document d’antériorité susceptible de favoriser la cause de son client. Cependant, la société a rapidement réalisé que le principal défi ne résidait pas dans la qualité des modèles d’IA, mais dans la capacité de l’infrastructure à traiter des volumes de données toujours plus importants. Passer d’une base de données de 40 millions de documents à un corpus mondial complet d’environ 450 millions de brevets a révélé des faiblesses critiques en termes de fiabilité et de temps de réponse.
Pour résoudre ce problème, Melange s’est associé à Pinecone, un fournisseur de bases de données vectorielles. Ash Ashutosh, PDG de Pinecone, explique que l’IA, en tant que moteur de raisonnement, a besoin d’une base de connaissances solide et constamment mise à jour. Sans une infrastructure capable de fournir un « rappel » élevé – c’est-à-dire la capacité à retrouver tous les documents pertinents – même le modèle d’IA le plus performant peut aboutir à des conclusions inexactes et coûteuses. Grâce à Pinecone, Melange a pu gérer plus de 600 millions de documents sans compromettre la fiabilité de ses recherches.
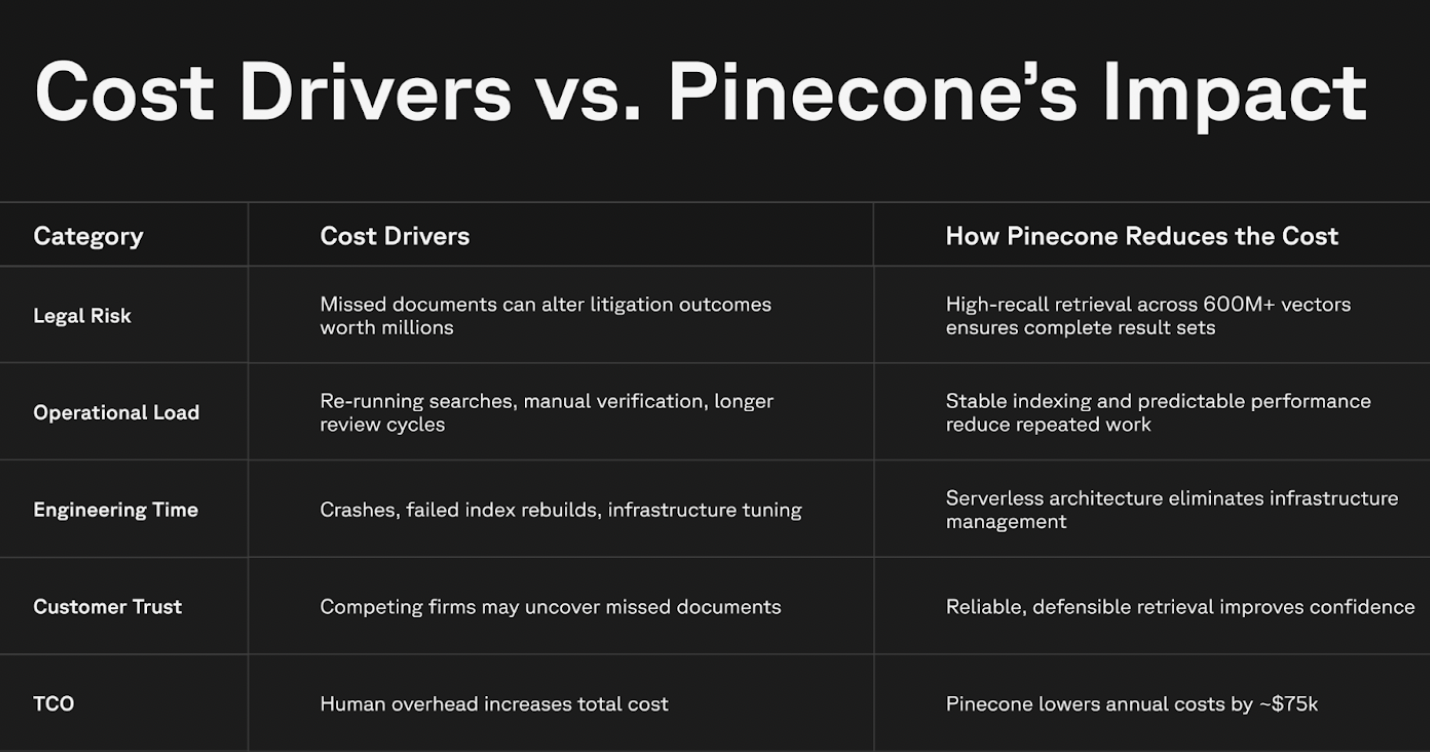
Joshua Beck souligne l’importance de ne pas se focaliser uniquement sur le modèle d’IA, mais de prendre en compte l’ensemble de l’infrastructure. Il appelle les professionnels du droit à s’interroger sur la capacité de leur système à traiter l’ensemble des données de manière fiable et précise. Si un fournisseur ne peut pas répondre à cette question de manière claire et convaincante, il est préférable de s’en tenir à d’autres solutions.
Ce problème ne se limite pas aux litiges en matière de brevets. La découverte de documents dans le cadre de procédures judiciaires plus classiques est également confrontée aux mêmes difficultés. Les experts discutent des limites actuelles du contexte et des solutions de contournement, mais la construction d’une infrastructure capable de gérer des volumes massifs de données reste un élément essentiel de l’équation. Car un modèle d’IA peut être précis, mais s’il est incomplet, il n’est pas pour autant fiable.
 Joe Patrice est rédacteur en chef chez Above the Law et co-animateur de Penser comme un avocat. N’hésitez pas à e-mail des conseils, des questions ou des commentaires. Suivez-le sur Twitter ou Bluesky si vous êtes intéressé par le droit, la politique et une bonne dose d’actualités sportives universitaires. Joe est également Directeur général chez RPN Executive Search.
Joe Patrice est rédacteur en chef chez Above the Law et co-animateur de Penser comme un avocat. N’hésitez pas à e-mail des conseils, des questions ou des commentaires. Suivez-le sur Twitter ou Bluesky si vous êtes intéressé par le droit, la politique et une bonne dose d’actualités sportives universitaires. Joe est également Directeur général chez RPN Executive Search.