

Publié le 18 octobre 2025. Une nouvelle analyse de l’écosystème de l’intelligence artificielle révèle des divergences notables dans l’évaluation des modèles, tandis que plusieurs acteurs majeurs lancent de nouvelles versions, promettant des avancées significatives.
Le Centre pour les normes et l’innovation en IA (CAISI) a récemment publié un rapport qui évalue DeepSeek 3.1, le comparant à des modèles propriétaires renommés. Cependant, les résultats présentés par le CAISI divergent de ceux déjà acceptés par la communauté scientifique. Si les benchmarks MMLU-Pro, GPQA et HLE montrent des scores de DeepSeek conformes aux déclarations et dans les marges d’erreur habituelles, les performances mesurées sur le banc SWE (un cadre logiciel essentiel pour l’évaluation des modèles agents) s’avèrent largement erronées. Cette inadéquation est attribuée à un « harnais » – l’environnement logiciel utilisé pour les tests – insuffisant, dont l’importance est comparable à celle du modèle lui-même, comme l’a souligné une analyse de Epoch AI.
En conséquence, le rapport du CAISI tendrait à sous-estimer les capacités des modèles DeepSeek sur un benchmark crucial pour les développements récents, utilisé notamment par Anthropic pour la commercialisation de ses modèles Claude. Les écarts observés sur les données de téléchargement de HuggingFace, où les chiffres du CAISI diffèrent de ceux du projet ATOM et de ceux de HuggingFace lui-même, témoignent de la complexité de l’analyse de cet écosystème. L’équipe d’ATOM précise adopter une méthodologie rigoureuse, ne retenant que les modèles publiés après ChatGPT et considérant exclusivement les grands modèles de langage (LLM). Cette approche exclut des modèles comme GPT-2, les architectures de type BERT, ou les vision transformers (ViT) tels que SigLIP, qui gonflent les statistiques de téléchargement de certains grands acteurs.
De plus, pour garantir la fiabilité des données, l’équipe ATOM applique un filtrage des valeurs aberrantes sur les téléchargements quotidiens, afin d’éviter que des pics exceptionnels, comme ceux observés pour Qwen2.5 1.5B (plus de 10 millions de téléchargements), ne faussent les résultats globaux. Les versions quantifiées de modèles (FP8, MLX, GGUF) sont également exclues du calcul pour éviter toute distorsion.
Parallèlement, le projet GPT-OSS d’OpenAI connaît un succès notable. Malgré des défis initiaux liés à son architecture (précision à 4 points) et à l’utilisation d’outils complexes, les modèles GPT-OSS 20B et 120B ont enregistré respectivement 5,6 millions et 3,2 millions de téléchargements le mois dernier. Ces chiffres surpassent ceux de modèles populaires tels que Qwen3 4B ou Qwen3-VL-30B-A3B-Instruct. Les retours de la communauté sont très positifs, et ces modèles sont considérés comme des candidats prometteurs pour les plateformes de calcul haute performance comme le Nvidia DGX-Spark.
Plusieurs annonces marquent également le paysage des modèles open-source :
-
Granite-4.0-h-small par IBM-granite : IBM continue de développer sa série de grands modèles de langage (LLM) Granite. La nouvelle génération propose des modèles hybrides (attention et Mamba) de tailles variées, allant de 3 milliards (3B) à 32 milliards de paramètres (32B-A9B MoE). La variante 3B se positionne aux côtés de SmolLM3, se distinguant par ses capacités multilingues et son suivi des instructions, bien que surpassée par Qwen3 4B sur ces aspects. Le ton de Granite 4.0 se veut plus sobre, rappelant l’approche des anciens modèles Mistral, et IBM prévoit de publier un modèle dédié au raisonnement plus tard dans l’année. L’approche hybride de « pensée » (activable par des invites), déjà introduite par IBM, permet d’activer ou désactiver des tokens de réflexion, une méthode qui s’avère complexe à entraîner mais qui a été adoptée par d’autres acteurs.
-
Qwen3-VL-235B-A22B-Instruct par Qwen : La série Qwen VL se met à jour avec des modèles denses de petite taille (4B, 8B) et des modèles plus imposants (30B-A3B, 235B-A22B) en versions « Instruct » et « Reasoning ». La version 8B est particulièrement mise en avant pour ses performances améliorées par rapport à la première itération, se positionnant comme une alternative solide aux modèles comme Llama3.1 8B.
-
GLM-4.6 par zai-org : Zhipu a dévoilé une nouvelle version de sa série GLM. Ce modèle est salué par la communauté comme étant l’équivalent chinois de Sonnet ou Haiku d’Anthropic, avec une gestion du contexte étendu qui le rend compétitif face aux modèles propriétaires, malgré une certaine perte de performance dans les contextes très longs. Cette sortie confirme la progression fulgurante des modèles open-source chinois, se rapprochant du niveau des meilleurs modèles fermés.
-
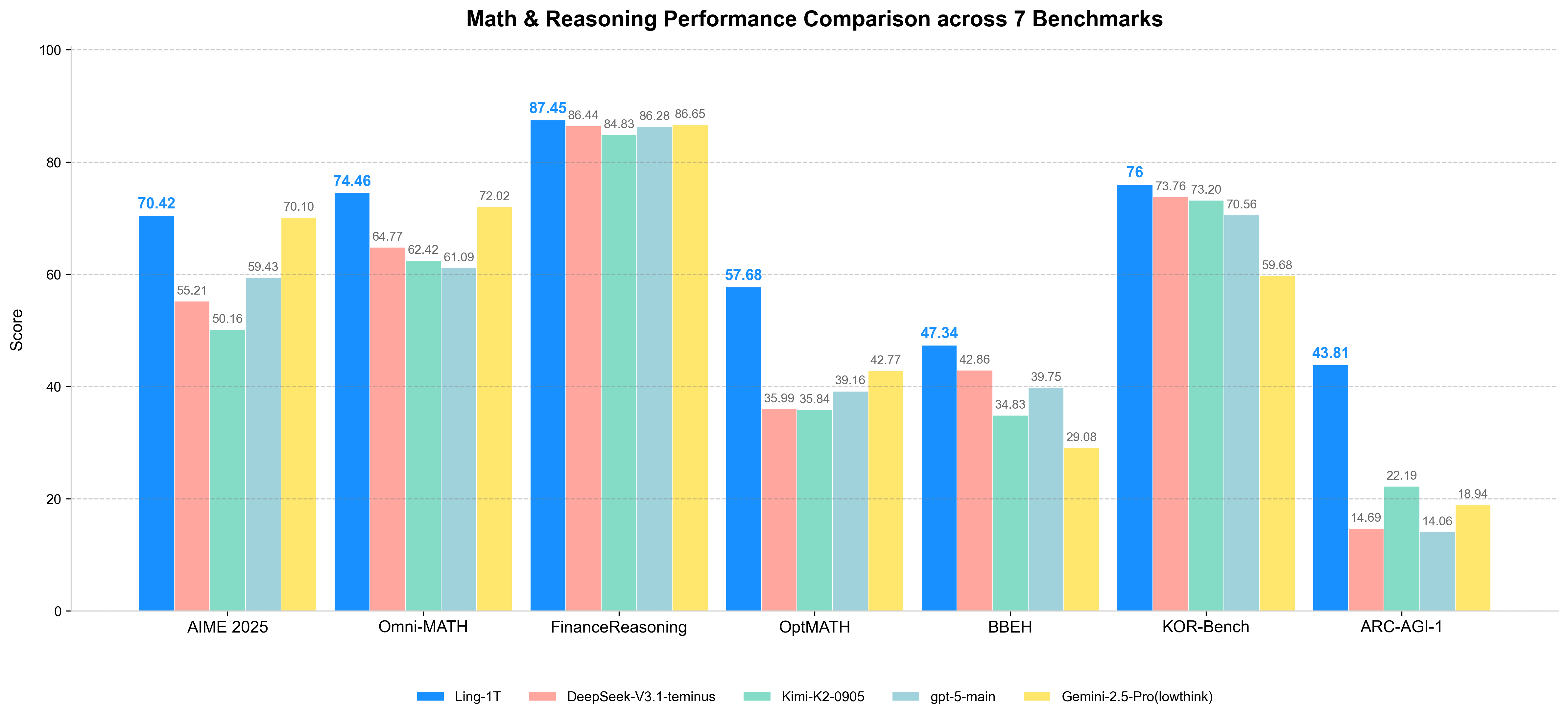
Ling-1T par inclusionIA : Inclusion AI accélère son rythme de publication avec des modèles atteignant désormais la taille impressionnante de 1 trillion de paramètres (1T). L’organisation expérimente différentes architectures et modalités, et propose également une version dédiée au raisonnement. Une version préliminaire (« preview ») de Ring-1T est également disponible.
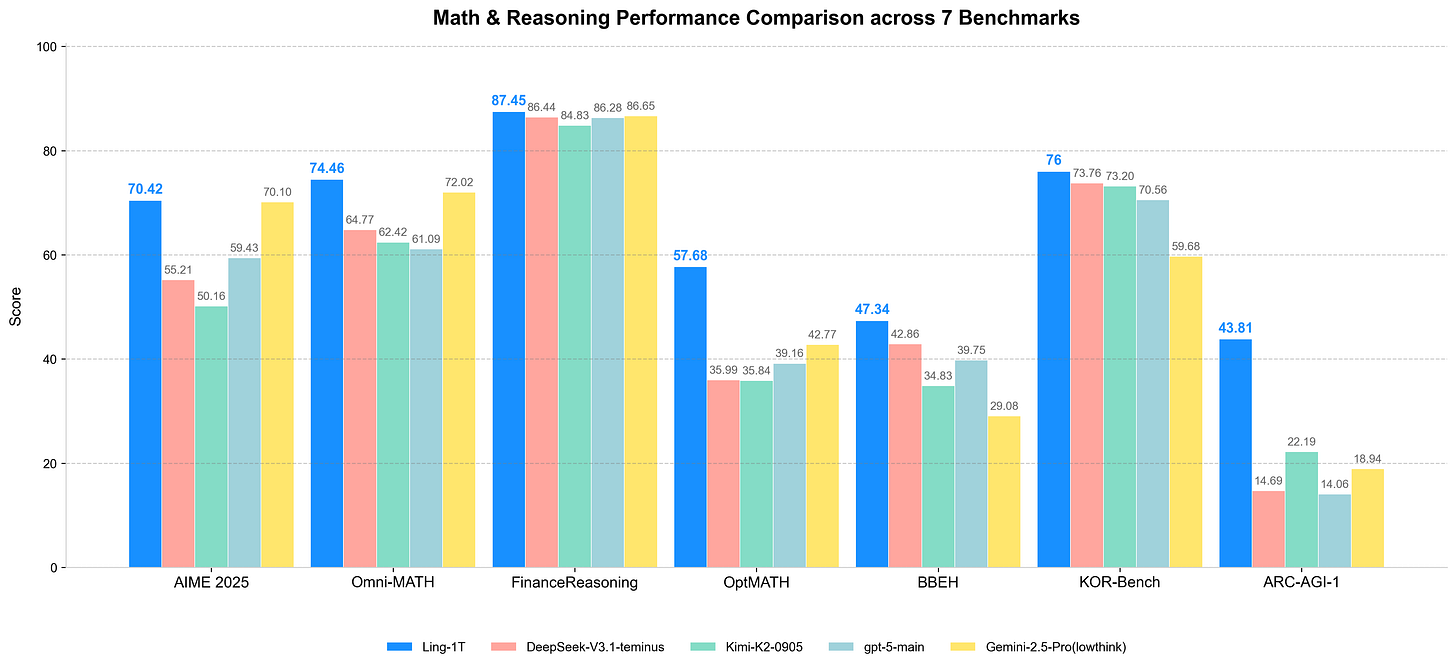
-
Moondream3-preview par moondream : Moondream, reconnu pour ses modèles performants malgré leur taille, adopte l’architecture MoE avec 9 milliards de paramètres actifs sur 2 milliards au total. Les performances ont été améliorées, et la licence d’utilisation est notable : elle autorise l’usage personnel, la recherche, et la plupart des applications commerciales, à condition de ne pas proposer un produit concurrentiel aux offres payantes de M87 Labs, comme la vente d’accès hébergé ou intégré.
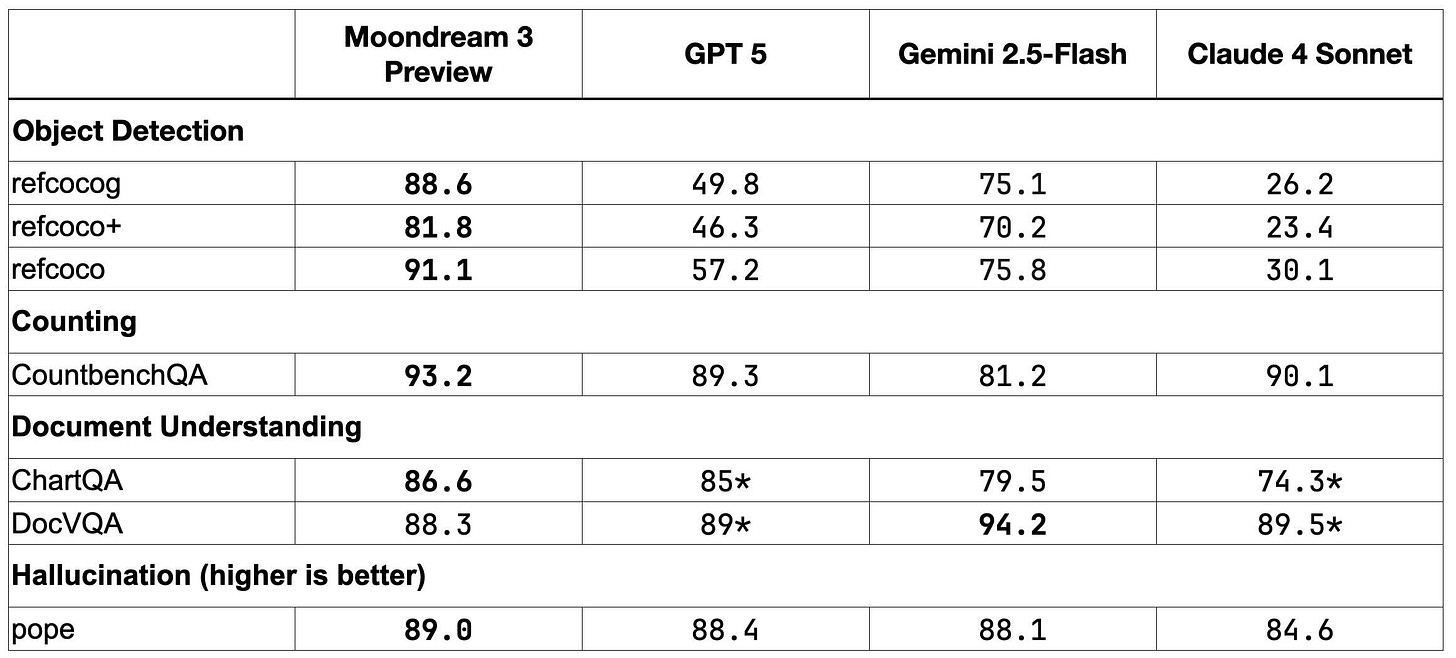
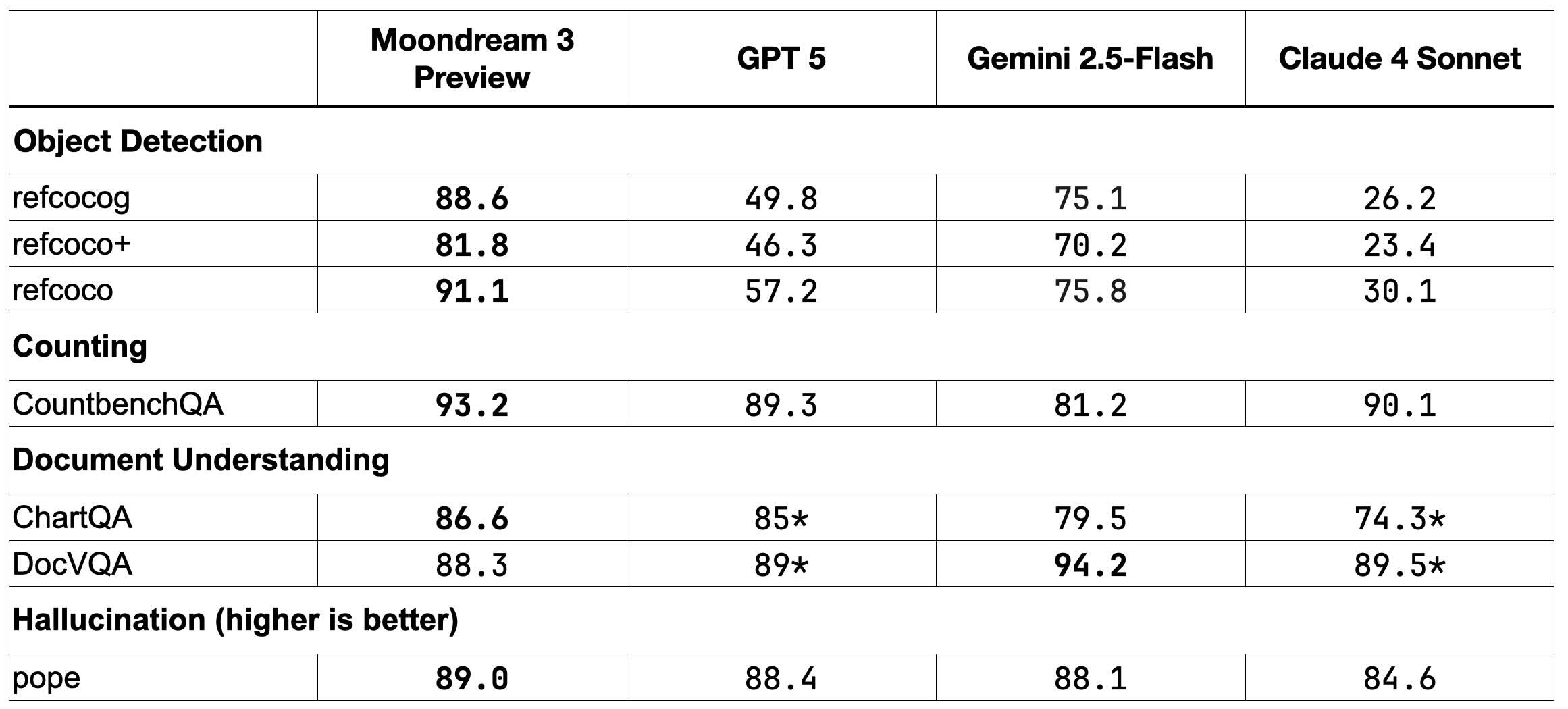
L’analyse de la « longue traîne » des modèles met en lumière la stratégie audacieuse de Qwen, soutenue par d’autres laboratoires chinois en plein essor. L’article souligne la difficulté persistante à trouver un ensemble de données d’évaluation répondant à des critères de pertinence élevés, laissant l’écosystème open-source dans une position précaire.
-
Qwen3-Next-80B-A3B-Instruct par Qwen : Qwen continue d’explorer de nouvelles architectures avec un LLM hybride, combinant Gated DeltaNet et Gated Attention. Entraîné sur plus de 15 billions (15T) de tokens, ce modèle pourrait servir de base aux futures générations de la série Qwen. L’équipe de développement a exprimé son ambition d’offrir une solution stable pour la gestion de contextes très longs.