

Publié le 8 février 2026 11:22:00. Les nouveaux modèles de raisonnement artificiel, comme Deepseek-R1, ne se contentent pas de traiter l’information plus longtemps : ils simulent un véritable débat interne, où différentes perspectives s’affrontent et se corrigent mutuellement pour résoudre des problèmes complexes.
- Les modèles de raisonnement génèrent une « société de pensée » interne, avec des voix simulées aux personnalités et expertises distinctes.
- Cette diversité de perspectives, mesurée selon cinq grands traits de personnalité, est corrélée à une meilleure performance en résolution de problèmes.
- L’amélioration artificielle des signaux conversationnels au sein du modèle double la précision sur des tâches mathématiques.
Une étude menée par des chercheurs de Google, de l’Université de Chicago et du Santa Fe Institute a révélé un fonctionnement surprenant des modèles de raisonnement avancés, tels que Deepseek-R1 et QwQ-32B. Ces modèles surpassent significativement les modèles de langage traditionnels dans la résolution de tâches complexes, et leur secret réside dans une forme de dialogue interne.
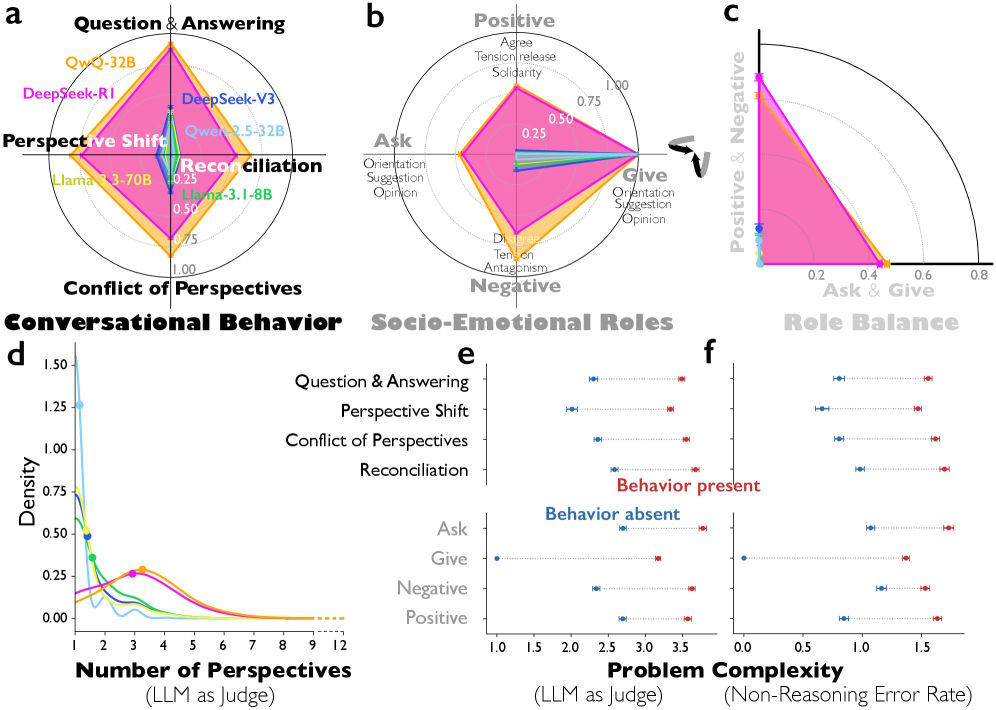
L’analyse de plus de 8 000 problèmes de raisonnement a mis en évidence des différences notables entre ces modèles et leurs homologues plus classiques, comme Deepseek-V3. Deepseek-R1, par exemple, présente une séquence beaucoup plus riche de questions-réponses et des changements de perspective plus fréquents. QwQ-32B, quant à lui, affiche des conflits de points de vue plus explicites que Qwen-2.5-32B.
Pour identifier ces dynamiques internes, les chercheurs ont utilisé une approche innovante, consistant à utiliser un autre modèle de langage, Gemini 2.5 Pro, comme « juge » pour évaluer les traces de raisonnement. Les résultats de cette évaluation ont été confirmés par des évaluateurs humains.
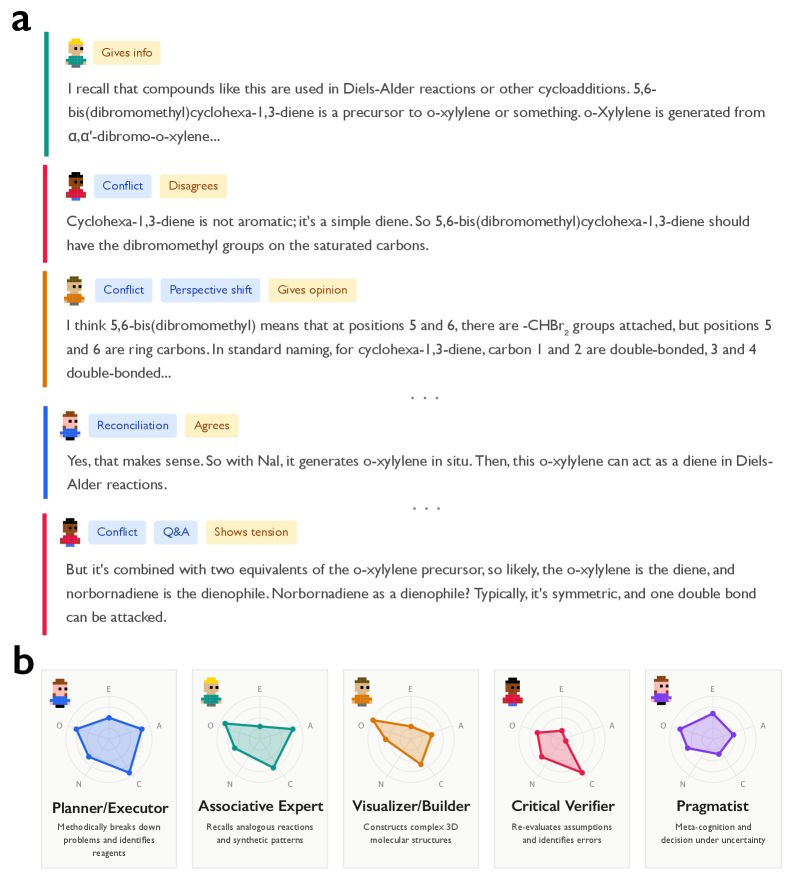
Un exemple concret illustre ce processus : lors de la résolution d’un problème de synthèse chimique complexe, Deepseek-R1 a manifesté un véritable débat interne, changeant de perspective et se corrigeant lui-même. À un moment donné, le modèle a même formulé l’observation suivante : « Mais ici, il s’agit de cyclohexa-1,3-diène, et non de benzène », détectant ainsi sa propre erreur en cours de réflexion. Deepseek-V3, en revanche, a suivi une approche plus linéaire, sans remise en question, et a abouti à une réponse incorrecte.
L’étude a également révélé que cette diversité interne se manifeste par une plus grande variété de personnalités au sein du modèle. Deepseek-R1 et QwQ-32B présentent une diversité significativement plus élevée que les modèles traditionnels, mesurée selon les cinq grands traits de personnalité : extraversion, agréabilité, conscience, névrosisme et ouverture d’esprit. Une exception notable est la conscience, qui semble être élevée dans toutes les « voix » simulées, suggérant une discipline et une diligence constantes.
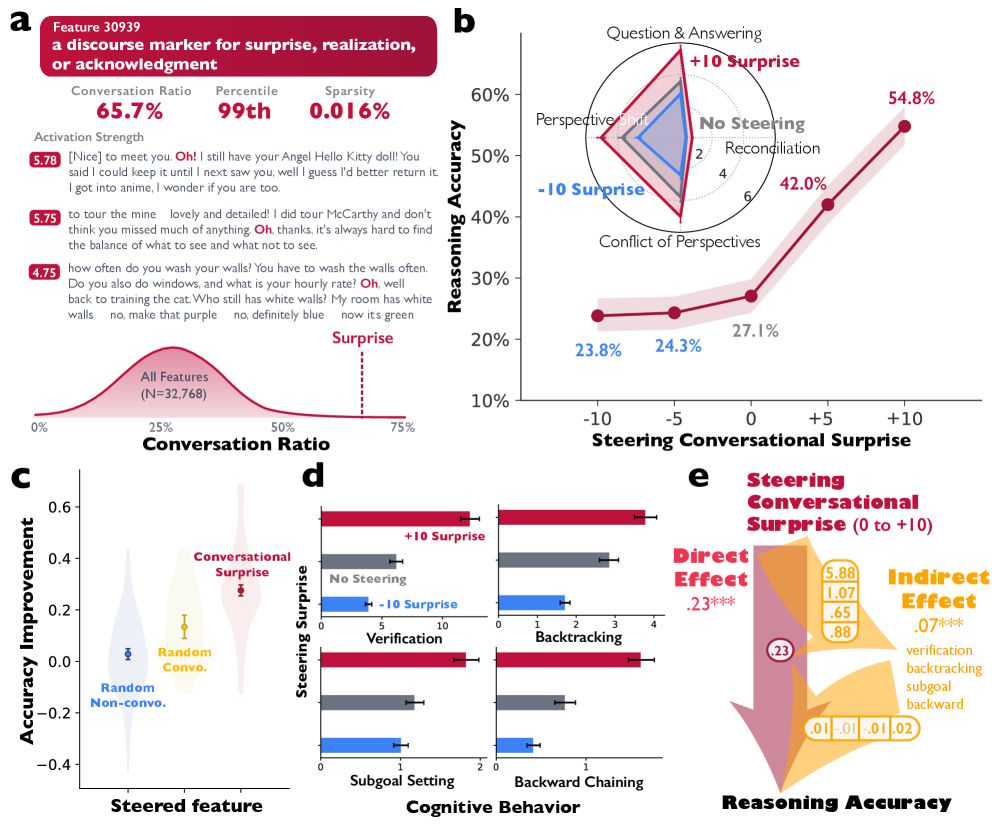
Pour vérifier si cette dynamique conversationnelle améliore réellement le raisonnement, les chercheurs ont utilisé une technique d’interprétabilité mécaniste. Ils ont identifié une fonctionnalité interne dans Deepseek-R1-Llama-8B, liée aux signaux conversationnels (surprise, prise de conscience, accusé de réception). En renforçant artificiellement cette fonctionnalité, ils ont constaté une augmentation de 54,8 % (passant de 27,1 %) de la précision sur une tâche mathématique. Le modèle a également manifesté un comportement plus conversationnel, vérifiant plus souvent ses résultats intermédiaires et détectant ses propres erreurs.
Des expériences d’apprentissage par renforcement ont confirmé que les modèles de base développent spontanément des comportements conversationnels lorsqu’ils sont récompensés pour leur précision, sans formation explicite sur les structures de dialogue. Cet effet est encore plus prononcé pour les modèles préalablement entraînés avec des processus de pensée de type dialogue.
Ces résultats font écho aux recherches sur l’intelligence collective dans les groupes humains. Mercier et Sperber, dans leur théorie de « l’énigme de la raison », soutiennent que la pensée humaine a évolué principalement comme un processus social. De même, la conception de Bakhtine du « soi dialogique » décrit la pensée humaine comme une conversation intériorisée entre différentes perspectives. L’étude suggère que les modèles de raisonnement reproduisent un parallèle informatique à cette intelligence collective : la diversité, lorsqu’elle est structurée, favorise une meilleure résolution des problèmes.
Les chercheurs soulignent qu’ils ne prétendent pas que les traces de raisonnement représentent une simulation de groupes humains ou d’un seul esprit imitant une interaction multi-agents. Cependant, les similitudes avec les équipes humaines performantes suggèrent que les principes d’une dynamique de groupe efficace pourraient offrir des pistes pour améliorer le raisonnement des modèles de langage.
Il est important de noter que, début 2025, des chercheurs d’Apple ont exprimé des réserves quant aux capacités de « réflexion » des modèles de raisonnement, soulignant que leur performance diminue avec la complexité des problèmes. D’autres études ont corroboré ces conclusions, bien que ce débat reste ouvert.